
A new Hadoop Cluster has been deployed in the School of Electronic Engineering and Computer Science, to be used for Big Data Teaching and Research. The cluster is comprised of a NameNode (Head Node) and 24 DataNodes.
In the current setup, the Head Node is called Andromeda and the DataNodes are named Leo nodes.
All of the EECS Student Desktops have the latest CDH 6.3.0 packages available along with custom configuration that allows students to send their jobs to the Hadoop Cluster with minimal configuration. The old studoop configuration has been replaced with the correspondent for andromeda on all Student Desktops and it can be found under /etc/hadoop/conf.andromeda
The jobs and data are submitted using the HDFS (Hadoop Distributed File System) on the Cluster, so the students’ disk quota on their EECS Home directory is not affected.
We are using the open-source version of CDH Cloudera Manager Express 6.3.0 to manage the Cluster’s Health, Services, Package deployment and to monitor the health of the running jobs. The following diagram explains the connectivity between the Student Desktops and the the Hadoop Cluster in EECS.
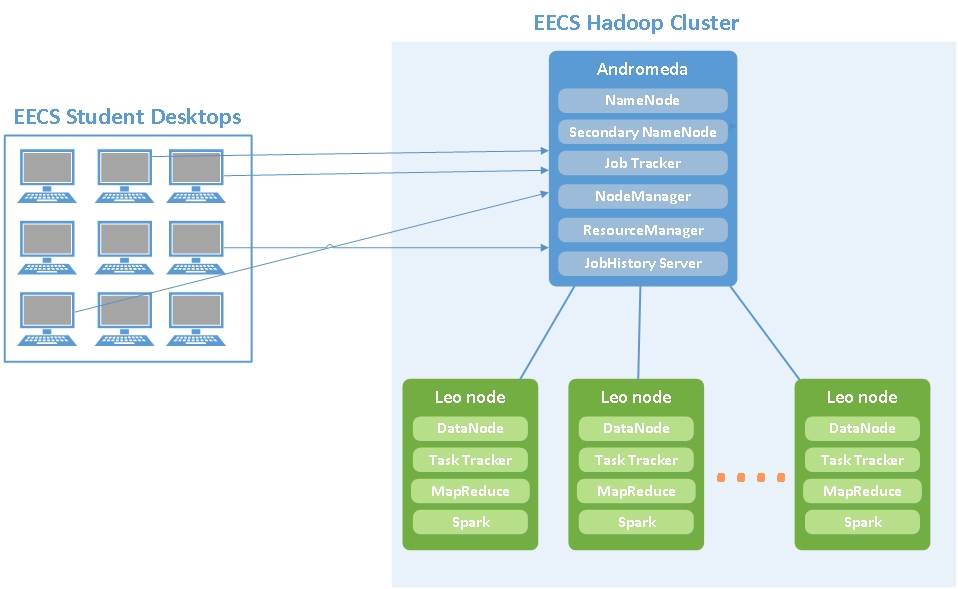
Hadoop Architecture
A Hadoop cluster is a special type of computational cluster designed specifically for storing and analyzing huge amounts of unstructured data in a distributed computing environment. The master node consists of a Job Tracker, Task Tracker, NameNode, and DataNode. A slave or worker node acts as both a DataNode and TaskTracker, though it is possible to have data-only and compute-only worker nodes.
HDFS nodes are managed through Andromeda, the dedicated NameNode server to host the file system index (and also a secondary NameNode) that can generate snapshots of the namenode’s memory structures, thereby preventing file-system corruption and loss of data. Similarly, a standalone JobTracker server can manage job scheduling across nodes.
Yarn
Apache Yarn is a part of Hadoop that can also be used outside of Hadoop as a standalone resource manager. NodeManager takes instructions from the Yarn scheduler to decide which node should run which task. Yarn consists of two pieces: ResourceManager and NodeManager. The NodeManager reports to the ResourceManager CPU, memory, disk, and network usage so that the ResourceManager can decide where to direct new tasks. The ResourceManager does this with the Scheduler and ApplicationsManager.
Apache Spark
Apache Spark is an open-source distributed cluster-computing framework. Spark is a data processing engine developed to provide faster and easy-to-use analytics than Hadoop MapReduce. Before Apache Software Foundation took possession of Spark, it was under the control of University of California, Berkeley’s AMP Lab.
Hadoop distributed file system (HDFS)
The Hadoop distributed file system (HDFS) is a distributed, scalable, and portable file system written in Java for the Hadoop framework.
A Hadoop is divided into HDFS and MapReduce. HDFS is used for storing the data and MapReduce is used for the Processing the Data. HDFS has five services as follows:
- Name Node
- Secondary Name Node
- Job tracker
- Data Node
- Task Tracker
Top three are Master Services/Daemons/Nodes and bottom two are Slave Services. Master Services can communicate with each other and in the same way Slave services can communicate with each other. Name Node is a master node and Data node is its corresponding Slave node and can talk with each other.
Name Node: HDFS consists of only one Name Node we call it as Master Node which can track the files, manage the file system and has the meta data and the whole data in it. To be particular Name node contains the details of the No. of blocks, Locations at what data node the data is stored and where the replications are stored and other details. As we have only one Name Node we call it as Single Point Failure. It has Direct connect with the client.
Data Node: A Data Node stores data in it as the blocks. This is also known as the slave node and it stores the actual data into HDFS which is responsible for the client to read and write. These are slave daemons. Every Data node sends a Heartbeat message to the Name node every 3 seconds and conveys that it is alive. In this way when Name Node does not receive a heartbeat from a data node for 2 minutes, it will take that data node as dead and starts the process of block replications on some other Data node.
Secondary Name Node: This is only to take care of the checkpoints of the file system metadata which is in the Name Node. This is also known as the checkpoint Node. It is helper Node for the Name Node.
Job Tracker: Basically Job Tracker will be useful in the Processing the data. Job Tracker receives the requests for Map Reduce execution from the client. Job tracker talks to the Name node to know about the location of the data like Job Tracker will request the Name Node for the processing the data. Name node in response gives the Meta data to job tracker.
Task Tracker: It is the Slave Node for the Job Tracker and it will take the task from the Job Tracker. And also it receives code from the Job Tracker. Task Tracker will take the code and apply on the file. The process of applying that code on the file is known as Mapper.
HDFS stores large files (typically in the range of gigabytes to terabytes) across multiple machines. It achieves reliability by replicating the data across multiple hosts, and hence theoretically does not require redundant array of independent disks (RAID) storage on hosts (but to increase input-output (I/O) performance some RAID configurations are still useful). With the default replication value, 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to rebalance data, to move copies around, and to keep the replication of data high. HDFS is not fully POSIX-compliant, because the requirements for a POSIX file-system differ from the target goals of a Hadoop application.